19.1. Intro to Parallel Computing#
19.1.1. Parallelizing Computations in High-Performance Computing (HPC)#
Parallel computing is a technique used to enhance computational speeds by dividing tasks across multiple processors or computers/servers. This section introduces the basic concepts and techniques necessary for parallelizing computations effectively within a High-Performance Computing (HPC) environment.
19.1.1.1. Loosely vs. Tightly Coupled Parallelism#
Loosely Coupled Parallelism: In this model, each processor operates independently, with minimal need for communication. This is often used in distributed computing environments where tasks do not require constant interaction.
Tightly Coupled Parallelism: Contrasts with loosely coupled parallelism by featuring processors that work in close coordination, often requiring frequent data exchanges. This model is typical in systems with shared memory.
19.1.1.3. Parallel Programming Models#
Parallel programming models are frameworks or paradigms that guide the development of parallel software.
Message Passing Interface (MPI): A standard for passing messages between processes in a distributed memory system. Ideal for high scalability across multiple nodes.

Fig. 19.1 MPI Workflow Diagram (Credit: hpc.nmsu.edu)#
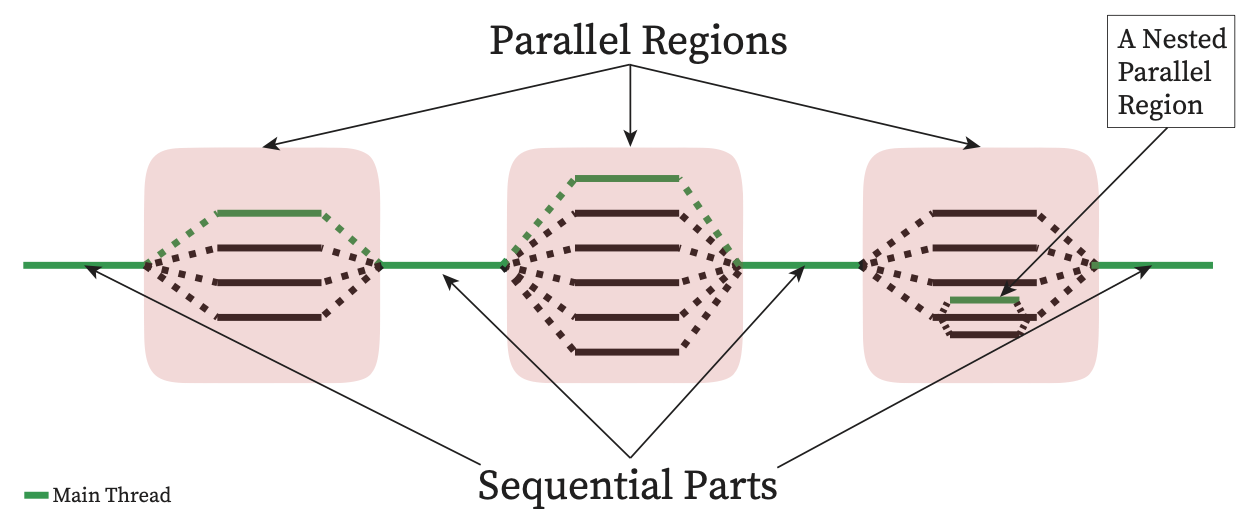
OpenMP (Open Multi-Processing): A model for shared-memory parallelism, suitable for multi-threading within a single node. It simplifies parallelism by allowing the addition of parallel directives into existing code.
CUDA (Compute Unified Device Architecture): A parallel computing platform and application programming interface (API) model created by NVIDIA. It allows software developers to use a CUDA-enabled graphics processing unit (GPU) for general purpose processing.

Fig. 19.3 CUDA Programming Model Diagram (Credit: nvidia.com)#