19.2. GPU Computing#
19.2.1. GPU vs CPU Computing#
The difference in CPU and GPU computing capabilities comes from their design. CPUs are designed to execute a sequence of instructions (aka thread) as fast as possible and with multicore design to run multiple threads simultaneously, mostly targeting lower response time. While GPU design focuses on providing higher throughput by executing thousands of threads concurrently by providing more computing resources aiming to excel parallel workloads efficiently.
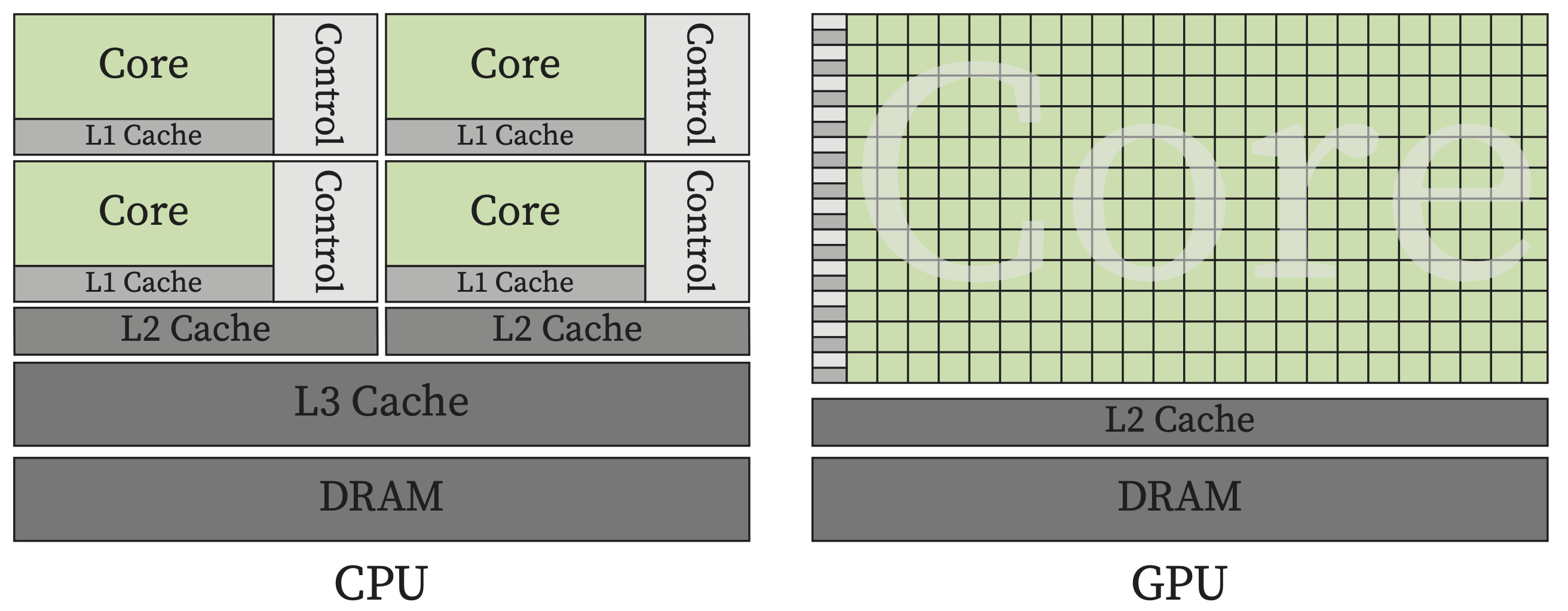
Fig. 19.4 GPU design provides vastly greater compute resources particularly for parallel workloads#
19.2.2. How to use GPUs#
Here is how we can utilize the compute power of GPUs for Matrix Multiplication using the CuPy package (equivalent of NumPy for GPUs).
Matrix Multiplication Using CuPy on GPU vs NumPy on CPU
import numpy as np
import cupy as cp
import time
# Matrix size
n = 10000
# Function to perform matrix multiplication on CPU
def matrix_multiplication_cpu():
# Initialize matrices with random values
A = np.random.randn(n, n)
B = np.random.randn(n, n)
# Measure time for matrix multiplication
start_time = time.time()
C = np.dot(A, B)
end_time = time.time()
# Return time taken
return end_time - start_time
# Function to perform matrix multiplication on GPU
def matrix_multiplication_gpu():
# Initialize matrices with random values
A = cp.random.randn(n, n)
B = cp.random.randn(n, n)
# Measure time for matrix multiplication
start_time = time.time()
C = cp.dot(A, B)
# Synchronize to ensure all GPU operations are complete
cp.cuda.Stream.null.synchronize()
end_time = time.time()
# Return time taken
return end_time - start_time
# Perform on CPU
cpu_time = matrix_multiplication_cpu()
print(f"Time taken on CPU: {cpu_time:.6f} seconds")
# Perform on GPU if available
gpu_time = matrix_multiplication_gpu()
print(f"Time taken on GPU: {gpu_time:.6f} seconds")
Output:
Time taken on CPU: 23.157653 seconds
Time taken on GPU: 7.113699 seconds
Alternatively PyTorch provides a very efficient built-in function for matrix multiplication.
Matrix Multiplication Using PyTorch on GPU vs CPU
import time
import torch
# Start timer for the whole script
start_time_script = time.time()
# Matrix size
n = 1000
# Initialize matrices with random values
A = torch.randn(n, n)
B = torch.randn(n, n)
# Measure time for CPU operation
start_time_cpu = time.time()
C_cpu = torch.matmul(A, B)
end_time_cpu = time.time()
print(f"Time taken on CPU: {end_time_cpu - start_time_cpu:.6f} seconds")
# Check if a GPU is available
if torch.cuda.is_available():
# Move matrices to GPU
A_gpu = A.to('cuda')
B_gpu = B.to('cuda')
# Warm-up GPU
torch.matmul(A_gpu, B_gpu)
# Synchronize and measure GPU time
torch.cuda.synchronize()
start_time_gpu = time.time()
C_gpu = torch.matmul(A_gpu, B_gpu)
torch.cuda.synchronize()
end_time_gpu = time.time()
print(f"Time taken on GPU: {end_time_gpu - start_time_gpu:.6f} seconds")
else:
print("No GPU available.")
# End timer for the whole script
end_time_script = time.time()
print(f"Total script execution time: {end_time_script - start_time_script:.6f} seconds")
Output:
Time taken on CPU: 0.379145 seconds
Time taken on GPU: 0.000208 seconds
Total script execution time: 2.112846 seconds
19.2.3. More Frameworks and Libraries#
In addition to the aforementioned CuPy and PyTorch, there are many more Frameworks and Libraries that enable applications to run computation on GPUs.
19.2.3.1. Nvidia RAPIDS#
TBD
19.2.3.2. Pytorch Lightning#
TBD